**Previous Episode: [[BDE370 ]]**
**Next Episode: [[BDE372 ]]**
%%Post image thumbnail below.%%

> [!abstract|no-i] **Episode Overview**
**Date Aired:** [[10-15-2024]]
**Title:** Not Exactly All The Wayback
**Episode:** 371
**Description:** A crash course on taking notes & keeping information safe. For when the failsafe fails.
**Link:** https://rumble.com/v5itkzx-big-dig-energy-371-not-exactly-all-the-wayback.html
**Tags:** #BigDigAcademy
%%<https://historydraft.com/happened/what-happened/1-January/world>%%
## Replay
%% Get embed URL then highlight and hit ALT + I%%
<iframe src="https://rumble.com/embed/v5gkfnx/?pub=6eeyh" allow="fullscreen" allowfullscreen="" style="height:100%;width:100%; aspect-ratio: 16 / 9; "></iframe>
<br>
## Greetings & Announcements
## Segments
<p style="font-size:125%"><b><font color="#ffffff"> What we call history is only the Now of an earlier time, recorded and preserved as best we can and reconsidered afterward. There is no complete and knowable record of any part of the past, no magical, permanently accurate “history.” — Maria Bustillos</font></b></p>
### What's Up With the Wayback Machine?
#### Key Info
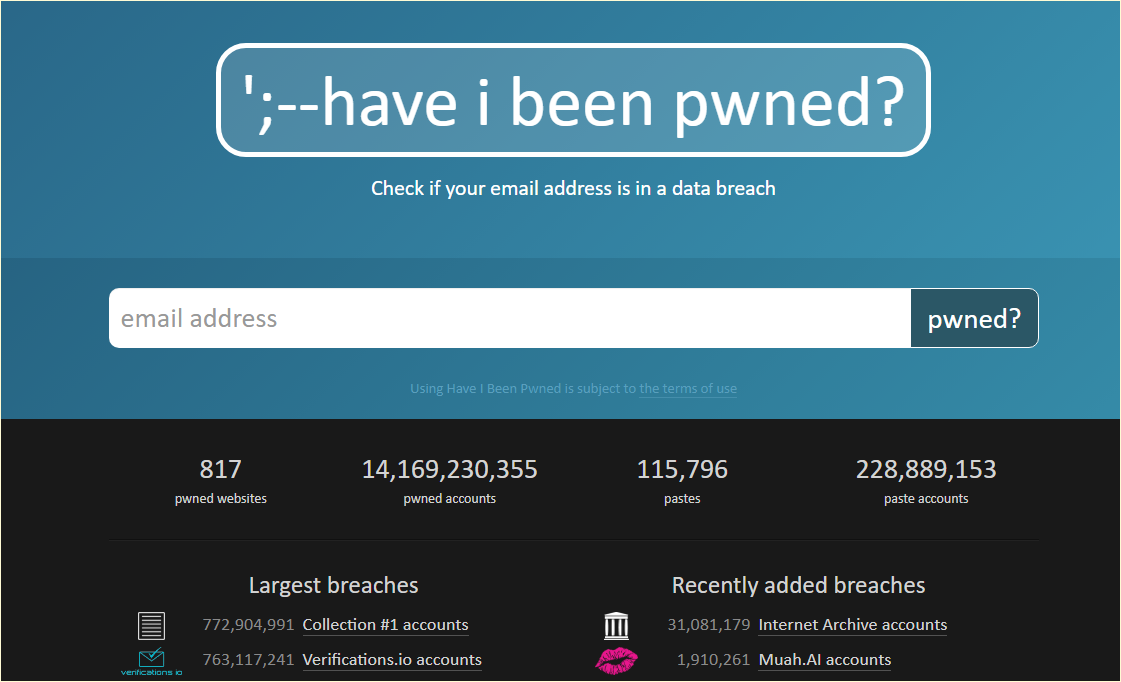
- Data breach containing 31 million unique email addresses along with usernames, bcrypt password hashes, and other system data. — **[Internet Archive hacked, data breach impacts 31 million users](https://www.bleepingcomputer.com/news/security/internet-archive-hacked-data-breach-impacts-31-million-users/)**
- 
- The text "HIBP" refers to the Have I Been Pwned data breach notification service created by Troy Hunt, with whom threat actors commonly share stolen data to be added to the service.
- 
- Claimed by the BlackMeta hacktivist group, who said they would conduct additional attacks.
- 
- Confirmed by Internet Archive founder Brewster Kahle.
- 
- Update as of two days ago:
- 
- Three hours ago:
- 
#### Google Cached View Ended Two Months Ago

Solution: Run it through the Wayback Machine.

### What is the Internet Archive?
> The Internet Archive is an American nonprofit digital library website founded in 1996 by Brewster Kahle. It provides free access to collections of digitized materials including websites, software applications, music, audiovisual, and print materials. The Archive also advocates a free and open Internet. As of September 5, 2024, the Internet Archive held more than 42.1 million print materials, 13 million videos, 1.2 million software programs, 14 million audio files, 5 million images, 272,660 concerts, and over 866 billion web pages in its Wayback Machine. Its mission is committing to provide "universal access to all knowledge".
>
> - [Wikipedia](https://www.wikiwand.com/en/articles/Internet_Archive)
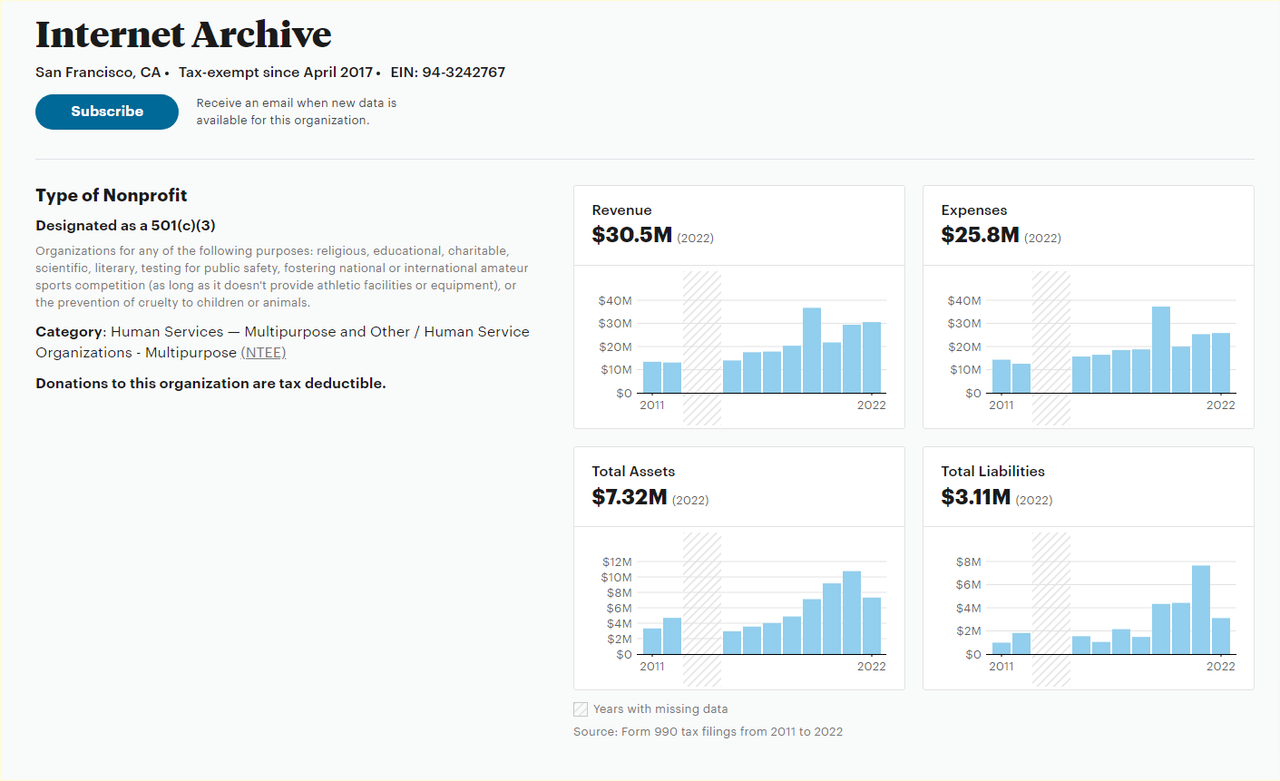
2022 Form 990PF:
**Mission**: Internet Archive was founded in 1996 to build an Internet library with the purpose of offering permanent access for researchers, historians and scholars to historical collections that exist in digital format including texts, audio, movies, images, software and web pages.
<div style="left: 0; width: 100%; height: 0; position: relative; padding-bottom: 60%;"><iframe src="https://docs.google.com/viewer?embedded=true&url=http://sbik.site.nfoservers.com/PDFs/Form-990PF/Internet-Archive-2022-990.pdf" style="top: 0; left: 0; width: 100%; height: 100%; position: absolute; border: 0;" allowfullscreen></iframe></div>
Further Reading: [How the Internet Archive is Digitizing LPs to Preserve Generations of Audio](https://blog.archive.org/2019/10/25/how-the-internet-archive-is-digitizing-lps-to-preserve-generations-of-audio/)
> - The Internet Archive partners with Innodata Knowledge Services, an organization focused on machine learning and digital data transformation, to complete the digitization process.
### Digital Preservation: What's At Stake
<p style="font-size:125%"><b><font color="#ffffff"> 310,000,000,000 — The number of web pages captured over time by the Internet Archive’s Wayback Machine as of 2018.</font></b></p>
**From *[Ensuring the Longevity of Digital Information](https://www.clir.org/wp-content/uploads/sites/6/ensuring.pdf)* ** — February 1999

> Although there are few well-documented, undisputed cases of important digital documents or data that have been irretrievably lost, anecdotal evidence abounds. One of the best publicized cases concerns U.S. Census information for 1960.
>
> This was originally stored on digital tapes that became obsolete faster than expected. Although some information on these tapes was apparently unreadable, most of it was successfully copied onto newer media, and it appears that nothing irreplaceable was lost (since the raw census returns were saved on microfilm).
>
> Nevertheless, this case represents a narrow escape and is cited prominently in the 1990 House of Representatives Report Taking a byte out of history: the archival preservation of federal computer records (Nov. 6, 1990, House Report 101-978).
<div style="left: 0; width: 100%; height: 0; position: relative; padding-bottom: 60%;"><iframe src="https://docs.google.com/viewer?embedded=true&url=http://sbik.site.nfoservers.com/PDFs/US%20Gov/Byte-of-History.pdf" style="top: 0; left: 0; width: 100%; height: 100%; position: absolute; border: 0;" allowfullscreen></iframe></div>
> The task of internet archivists has developed a significance far beyond what anyone could have imagined in 2001, when the Internet Archive first cranked up the Wayback Machine and began collecting Web pages; the site now holds more than 30 petabytes of data dating back to 1996. (One gigabyte would hold the equivalent of 30 feet of books on a shelf; a petabyte is a million of those.)
>
> - From **[Erasing History](https://www.cjr.org/special_report/microfilm-newspapers-media-digital.php)**
### How to Start Your Own Archive
**See: [[Big Dig Academy]]**
This is basically going to be an [Obsidian](https://obsidian.md/) commercial.
Available for Windows, iOS, Android, Mac, and Linux.
**Alternatives**: [FoamBubble](https://foambubble.github.io/foam/), Notion, Logseq, Anytype
Fair Warning: I cannot give individual tech help, so join the Discord and help each other if need be. Obsidian is very very easy, which is why I use it. ;)
#### What is Obsidian?
Obsidian is a powerful note-taking application that leverages the concept of linked concepts to organize and connect your knowledge base. Its bidirectional linking system allows you to create a web of interconnected notes, enhancing the ability to navigate through and comprehend complex topics.
It supports the integration of various media types, such as images, PDFs, and spreadsheets, making it a versatile, while remaining fairly simple.
Obsidian uses your local file system, ensuring that all notes and data are stored on your device only, which makes it fairly secure.
Easy to Start: create a vault, take notes, and link them. Organize notes using folders and tags. Customize the interface and publish notes as a website or share as PDF/HTML. It's flexible and versatile, encouraging experimentation.
##### Markdown
One distinctive feature of Obsidian is its support for [[Markdown]], a lightweight markup language that enables you to format text easily and efficiently. This integration allows for seamless conversion of plain text notes into beautifully styled documents, enabling a more visually appealing and reader-friendly experience. Furthermore, Obsidian's graph view gives you a visual representation of the connections between notes, facilitating a deeper understanding of the relationships and patterns within the knowledge base.
See: https://www.markdownguide.org/getting-started/
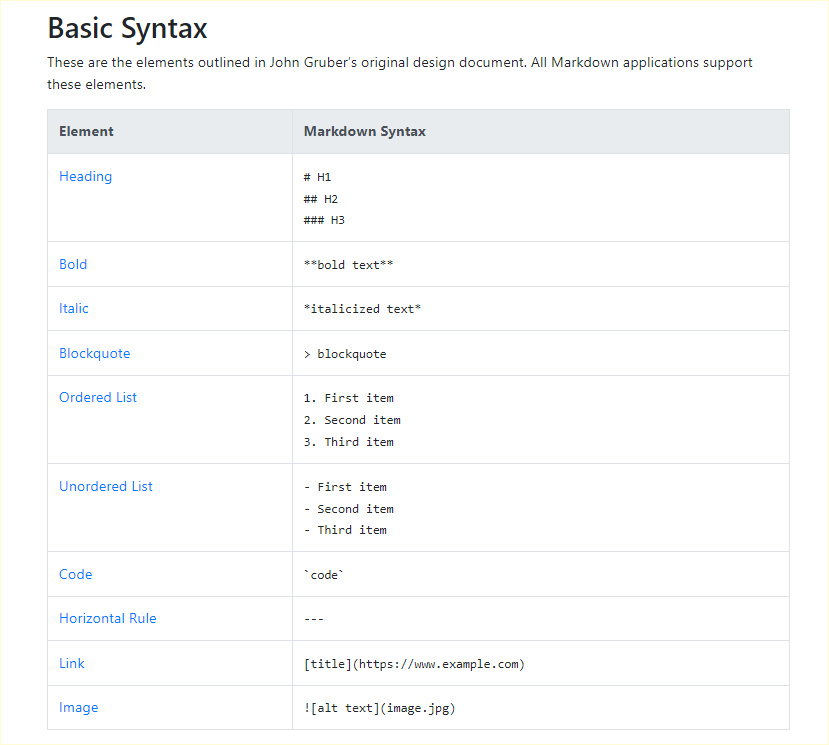
Obsidian also supports advanced Markdown features such as tables, image embedding, inline math formatting, and collapsible sections. You can create more complex and visually appealing notes while maintaining the flexibility of plain text. Moreover, Obsidian's live preview feature allows you to see your formatting in real-time, making it easier to ensure that notes are formatted as intended.
##### Backlinking Makes the Archive Work
Backlinking is a core feature of Obsidian that allows you to create connections between notes by creating links. These links point to related notes and act as bidirectional connections, providing a seamless way to navigate through your knowledge base. By utilizing backlinks, you can establish a network of interconnected information, enhancing the discoverability and coherence of your notes.
The backlinking system in Obsidian is intuitive and powerful. It enables you to easily create links between notes by using double square brackets `[[note name]]`. These links are automatically transformed into backlinks within the note, showing you all the other notes that reference it. This bidirectional linking creates a web of connections, allowing you to jump between related notes effortlessly and explore ideas in a non-linear manner.
<u>**Tool: SQID**</u>
With the backlinking system, you can leverage the power of associative thinking and connect different concepts. By following backlinks, you can discover new relationships and patterns within your notes, fostering a deeper understanding of your knowledge base. Whether you want to build a personal wiki, manage research projects, or organize your ideas, the backlinking system in Obsidian provides a flexible and effective way to structure and explore your information.
##### We build knowledge/Archives non-linearly
I built out my categorization system over several years, which operates on a set standard of Nested Hierarchies.
- Provides a multi-level structure that allows for a more granular classification of content.
- This approach enables the creation of categories within categories, offering a way to group related information in a detailed and interconnected manner.
- Mirrors the way you (or at least I) think and works with my brain instead of against it.
- This plays a crucial role in enhancing scalability and flexibility within information organization. As the volume of data grows, it accommodates the increasing complexity by providing a versatile framework for expanding and refining the organization of knowledge.
Broad Categories: https://www.bigdigenergy.info/index
My Own Projects: https://www.bigdigenergy.info/projects
Matched with the Archive: https://www.bigdigenergy.info/archives
The Toolbox: https://www.bigdigenergy.info/toolbox
Crucial:
- Obsidian
- Inoreader (or RSS feed)
- Newspapers
- Libgen.is
- Sci-hub.se
- Alternativeto.net
- ArchiveBox/Backblaze
### On the Next (few):
- Setting up web archiver.
- PANDOC - document conversion and storage
- How to display archived pages.
- Metadata
Let me know what sounds most helpful and I will try to prioritize that way.
(If we have time, long term goal of Wayback alternative with Datatools baked in/social aspect.)
%%Footer Starts Here%%
---
![[Brain Icon 1.png|center]]
<b><font color="#ffffff"> <center>You might not have noticed it… but your brain did.</center> </font></b>
---
### Tags
#BigDigAcademy
### Linked Pages & Footnotes
See: [[Big Dig Academy]]
Not found
This page does not exist